

Engagement BigQuery
Engagement BigQuery (EBQ) is a petabyte-scale data storage solution that exports your Bloomreach Engagement data to Google BigQuery. It provides secure, scalable storage with read-only access for custom analytics using your BI tools.
Feature for advanced usersEBQ is for advanced users who have solid experience with Google BigQuery, SQL, big data and data warehouse solutions.
What is EBQ?
EBQ stores your Bloomreach Engagement data in Google BigQuery with an Engagement-like structure. This lets you run custom analytics and create reports using your preferred BI tools.
NoteContact your CSM to enable EBQ in your project.
Key features
- Data updates: Events load every 6 hours, customer data loads daily.
- Access: Read-only through BigQuery Console, client libraries, or GCP service accounts.
- Retention: 10-year rolling window (9 years past, 1 year future).
- Data types: Events and customer properties.
Important considerations
- EBQ exports Bloomreach data to BigQuery. BigQuery Integration imports data from BigQuery into Bloomreach.
- EBQ isn't a backup solution. Re-importing deleted data requires your initiative and cost.
Data retention rules
- Events older than 9 years are deleted from EBQ.
- Events dated more than 1 year in the future are discarded.
- Customer profile deletions in Bloomreach also delete from EBQ (customer IDs and attributes).
- Event deletions in Bloomreach don't delete from EBQ automatically.
Prerequisites
- Google account (user or service account) to access BigQuery Console.
- GCP service accounts aren't created automatically. Contact your Customer Success Manager (CSM) to request one.
Google account neededYou can create a Google account with your existing company email. Consider creating a GSuite for Business account.
Frequency of data-updateThe data in EBQ updates once a day for customer attributes and IDs, and four times a day for events.
Benefits
- Scalable infrastructure that grows with your business.
- Engagement-like data structure for easy analysis in third-party tools.
- Advanced security and threat detection.
- 10-year data retention.
- Team-based access management.
- Usage-based pricing.
- Google BigQuery and third-party app support.
Access your data
There are several ways to access your EBQ data, which is loaded in BigQuery.
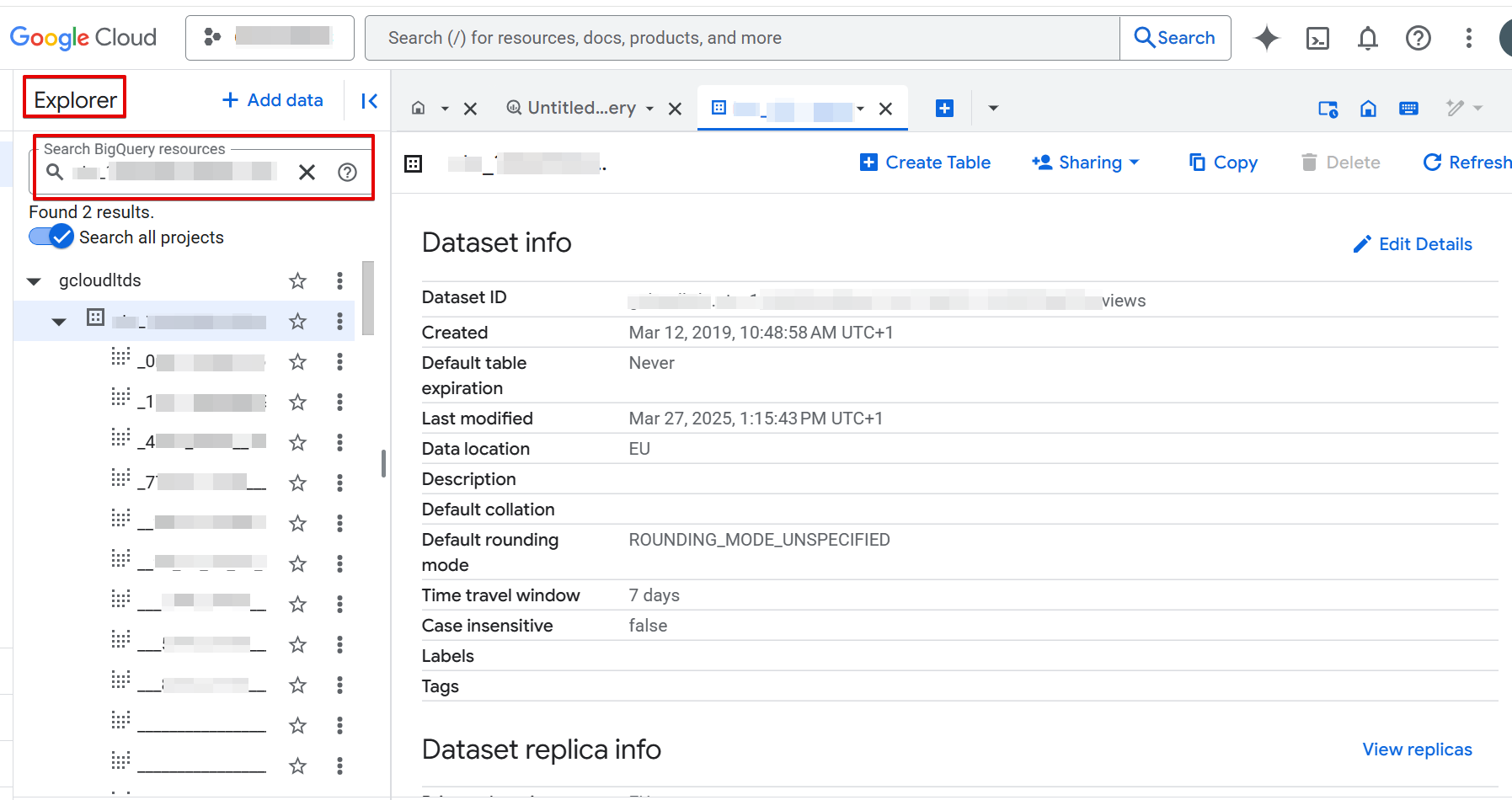
BigQuery Console
- Log in to BigQuery Console with your Google account.
- Search for your dataset using the Explorer sidebar (Search BigQuery resources).
- Type your dataset ID or name.
- Enable Search all projects to include all available datasets.
- Star (bookmark) the dataset for easier access.
Troubleshooting access:
- Make sure you're in the GCloudLTDS project, not your own BigQuery project.
- Always search by dataset ID, not just name.
- Star datasets you find. Links to datasets can expire.
- If you don't see the dataset, confirm you're using the Google account your CSM added to the access group.
BI tools
To create reports and analyses using EBQ data, connect BI tools that support BigQuery connectors:
- Tableau
- Power BI
- Qlik
- Google Data Studio
JDBC/ODBC drivers
Install JDBC/ODBC drivers for tools without native BigQuery connectors (like ETL tools).
BigQuery API
Access data programmatically using Google Cloud Client Libraries.
Third-party toolsBloomreach can't guarantee availability, performance, or compatibility of third-party tools with EBQ because they are developed, maintained, or licensed by external vendors.
Some tools may require additional permissions to access BigQuery datasets. These are not granted by default when EBQ is enabled due to security reasons. This can lead to offloading data from EBQ to another dataset where such permissions are granted.
Use the web-based BigQuery console. You can use it to write your custom SQL queries and store and execute them.
- If you don't see the dataset after receiving access from your CSM, ensure you are switched into the Google account that your CSM used to add you to a group on your browser and try loading the BigQuery console again.
User management
- Google Groups: Your CSM manages user access through a Google Group. Only group members can access your data. You don't need to accept Google Group invitations—your CSM adds members directly.
- User accounts: Use your Google user account to analyze data in BigQuery Console and access BI tools.
- Service accounts: A service account is a special accounts used by applications instead of people. Request one from your CSM for API access. If you already have one, contact your CSM for more information, if your existing one can be used for EBQ.
- User access and security policy: Bloomreach reviews accounts inactive for more than 180 days. Inactive accounts may be revoked to protect system security. This action is vital for system integrity and protection against security threats, including unauthorized access.
- Permissions:
- Read-only access: You can't edit data in EBQ.
- Project level: BigQuery Job User role.
- Dataset level: BigQuery Data Viewer role.
- API access: BigQuery API only (not BigQuery Storage API).
Review information on IAM roles in the official BigQuery documentation.
Data schema
EBQ is a set of tables in the Google BigQuery (GBQ) dataset that is kept up to date using regular loads. A BigQuery project always contains 2 types of tables.
EBQ isn't a backup of deleted dataIf you want to re-import data from EBQ, EBQ isn't a backup solution for deleted data. Any re-import must be handled at your initiative and cost. If you need help, contact your CSM to arrange support from a technical consultant.
Event tables
- One table per event type (for example, session_start, item_view).
- Loaded incrementally—new rows added with each load.
- Contains tracked data in the same structure as Bloomreach Engagement.
Properties field: All tracked data stored as a properties record accessible in SQL:
SELECT properties.utm_campaign FROM
`gcloudltds.exp_558cba14_8a46_11e6_8da1_141877340e97_views.session_start`The first 3 columns in each Event table are:
| Column | Description |
|---|---|
| internal_customer_id | Customer ID for joining with customer tables. |
| ingest_timestamp | When Bloomreach Engagement processed the event. |
| timestamp | When the event actually happened (business timestamp). |
To query those fields, no prefix needs to be used:
SELECT internal_customer_id FROM
`gcloudltds.exp_558cba14_8a46_11e6_8da1_141877340e97_views.session_start`
Customer tables
- Loaded daily using full load—tables rebuilt from scratch with latest data.
- Three main tables:
customers_properties,customers_id_history,customers_external_ids.
customers_properties: Main customer table with the same structure as Bloomreach Engagement.
All tracked data are stored as a “properties” record and can be accessed in SQL in the following way:
SELECT properties.last_name FROM
`gcloudltds.exp_558cba14_8a46_11e6_8da1_141877340e97_views.customers_properties`
customers_id_history: Tracks customer merges. Created only when customer merges exist in your project.
past_id: ID of merged customer.internal_customer_id: ID of customer that absorbed the merge.
Until customers are merged, there is no record in this table.

customers_id_history is missingView
customers_id_historyis created only when there are customer merges in the exported project.
customers_external_ids: Maps internal customer IDs to external IDs.
id_value: External customer ID value.id_name: Type of external ID (for example, cookie, email).
Properties schema
Both event and customer tables contain a properties field (BigQuery nested record). Field types map from Bloomreach Engagement types:
| Bloomreach Engagement type | BigQuery type |
|---|---|
| number | NUMERIC |
| boolean | BOOLEAN |
| date* | TIMESTAMP |
| datetime* | TIMESTAMP |
| list** | STRING |
| other | STRING |
date and datetime properties will be converted correctly only if their value is Unix timestamp in seconds. list type is stored in BigQuery in a JSON serialized form
In addition to properties field, customers, and event tables also contain raw_properties field. Properties in raw_properties field aren't converted according to Bloomreach Engagement schema, all of them are BigQuery STRING type. This is useful for cases when conversion in properties doesn't return expected results (the returned value is null).

Data namingSee any EBQ naming changes in
_system_mappingtable.
Data queries
Always use partitioned tables for faster, cheaper queries. EBQ tables partition on the timestamp column (business timestamp).
Example with partition filter::

A filter on the partitioned column has been used

A filter on the partitioned column hasn't been used
NoteNotice the difference in the volume of data to be processed (indicated in the bottom right part of the screenshots).
Monitor data loads
In order to enable monitoring of the load process, there is a table _system_load_log in each dataset. The main benefit of _system_load_log table is that it can act as a trigger for further data exports from your EBQ dataset. The common use case is to wait until you see an update in _system_load_log and then export new and updated data to another system. If you need to know how fresh are newly exported data in case of events, use max(ingest_timestamp).
For example to find out what was the last time when session_startisn't event type was loaded, the following query needs to be executed:
SELECT tabs, timestamp
FROM `gcloudltds.exp_4970734e_9ed3_11e8_b57b_0a580a205e7b_views._system_load_log`
CROSS JOIN unnest(tables) as tabs
WHERE tabs in('session_start')
ORDER BY 2 DESC
LIMIT 1And here is bit more complex example how to display last 4 table updates that were not updated in last 3 days. It can be used for example to display event tables that were not tracked into Bloomreach Engagement app for some period of time.
SELECT
loaded_table_name,
ARRAY_AGG(timestamp ORDER BY timestamp DESC LIMIT 4) as latest_updates -- limit to only X latest update timestamps for each table
FROM `gcloudltds.exp_c1f2061a_e5e6_11e9_89c3_0698de85a3d7_views._system_load_log`
LEFT JOIN UNNEST(tables) AS loaded_table_name
GROUP BY loaded_table_name
HAVING EXISTS (
SELECT 1
FROM UNNEST(latest_updates) AS table_timestamp WITH OFFSET AS offset
WHERE offset = 0 and DATETIME(table_timestamp) < DATETIME_SUB(CURRENT_DATETIME(), INTERVAL 3 DAY) -- show only table names where the latest update timestamp is older than 3 days
)
ORDER BY loaded_table_name ASCBest practices
Because unexpected delays in data processing may occur (especially during seasonal peaks), you should not rely on a specific time for new data to be exported and available in EBQ.
Instead, you should monitor the _system_load_log table and trigger dependent queries and scripts processing only after there is a log entry that data has been successfully exported to EBQ. If you run scripts on a fixed time, it may happen that the data is not exported to EBQ yet and it will run on an empty dataset.
Deleted events
Data in the event tables in the BigQuery are loaded incrementally and never deleted, even if you delete some data in Bloomreach Engagement. If you delete events in Bloomreach Engagement, these will not be deleted from EBQ. This means you will end up with BQ data that is inconsistent with the app. EBQ was developed to serve as a long-term storage with a 10-year rolling window of data retention, 9 years in the past and 1 year in the future, which means it retains data even after deletion within the app. If you want to discount invalid, bugged, or redundant event data (which you deleted in the app), you need to remember which deleted data and set up an additional filter in your reporting based on EBQ data.
Contact your CSM if you need help or further clarification.
Deletion vs. anonymization
Since you can't rely only on mirroring data deletion from app to EBQ, in case you are fulfilling data removal request (GDPR/CCPA), you will use anonymization functions in the app. Anonymization removes personal data also from EBQ, see Anonymizing customers.
Table_system_delete_event_typeIn releases before version 1.160 (Nov 2019), the information about deleted data was stored in EBQ in the table
_system_delete_event_type. You could use this table to filter only data that have not been deleted from Bloomreach Engagement. However this table is not updated anymore, after release of a feature Delete events by filter.
Merging customers
Every time a customer uses a different browser or device to visit your website, they are considered as separate and non-related entities. However, once the customer identifies (through registering or logging in their account for example), those 2 profiles are merged into one. In this way, customer activity can be tracked across multiple browsers and devices.
Until the customers are merged, there is no record of the first or the second customer in the customers_id_history table.
At the moment of the merge, the following information is stored in the table:
| internal_customer_id | customer_on_device_1 |
| past_id | customer_on_device_2 |
This means that the customer that was tracked on device 2 (customer_on_device_2) is merged into the customer on device 1 (customer_on_device_1), and both customers together are now considered as a single merged customer.
It is important to work with merged customers when you analyze the event data to get all events generated by the customer_on_device_2 and customer_on_device_1 assigned to a single customer. Use the following query to work with merged customers:
SELECT Ifnull(b.internal_customer_id, a.internal_customer_id) AS merged_id,
a.internal_customer_id AS premerged_id
FROM `gcloudltds.exp_558cba14_8a46_11e6_8da1_141877340e97_views.session_start` a
LEFT JOIN `gcloudltds.exp_558cba14_8a46_11e6_8da1_141877340e97_views.customers_id_history` b
ON a.internal_customer_id = b.past_idFor each internal_customer_id in the event table (session_start in this case) if there is a merge available in the customers_id_history, internal_customer_id will be mapped to the merged customer. As a result, analysis can be now done on merged_id, all session_starts created historically by either customer_on_device_2 or customer_on_device_1 will have merged_id = customer_on_device_1.
Anonymizing customers
When you anonymize a customer in Bloomreach Engagement, the data is also anonymized in the BigQuery.
Customer attributes marked as private are anonymized once a day. All customers and their attributes are replaced during a daily update from Engagement. If customer attributes are already anonymized, that anonymized (empty) value will be copied to EBQ customer tables as well.
Event properties marked as private are anonymized during processing event increments, at least once a day.
Technical steps of events anonymization:
- During anonymization through the app or API, an
anonymizationevent is tracked for the customer. Anonymizationevent is loaded into the BigQuery during a periodic data-update along with all the other events.- All the new
anonymizationevents are queried. - Anonymization is done by an
Updatequery for all theanonymizationevents queried in step 3 which contained acustomer_ID. This means that all the private event properties tracked for the particular customer IDs will be set to NULL. ltds_anonymization_timestampis tracked for all the anonymized events with a timestamp of the moment when the anonymization went through in the BigQuery.
Exports or recalculation of data with scheduled queries
With the EBQ, you can periodically run simple or calculate complex queries and store the results in another table within your BigQuery. Afterward, you can access and manipulate these results or use a BI tool, such as Tableau, to report on the data within this table.
The prerequisites for this are:
- You must have your own Google Cloud Platform (GCP) project with BigQuery (BQ) enabled
- You must have the BigQuery Data Transfer API enabled
- As a person configuring this, you must have
write accessto the BQ andread accessto EBQ
To configure scheduled queries, follow this guide:
- Open the relevant GCP and ensure that the active project is the desired GCP project and not GCloudLTDS (EBQ)
- Create a new dataset in the BQ at the same location as EBQ (EU)
- Create a new Scheduled query, as shown in the images below
For exporting use case, we recommend querying the raw_properties fields in customers_properties and event tables, as these are always the same data type, independent of Bloomreach Engagement app Data Management settings.
More resources can be found on the official Google BigQuery documentation:
.png")
EBQ optimization best practices
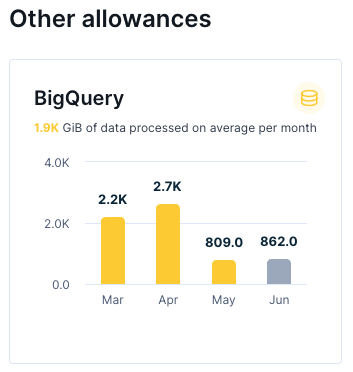
Monitor your EBQ usage
Check your EBQ usage in the Bloomreach usage dashboard under BigQuery allowance. Your contract usually includes the prepaid allowance. If your usage is over the allowance, you may be charged for overuse. Check your contract for more details.
To maximize EBQ's cost efficiency, it is important to apply a two-pronged optimization approach. First, follow the general best practices recommended for Google BigQuery—these foundational techniques remain relevant and effective in EBQ.
Second, use EBQ-specific recommendations tailored to our platform. Both types of optimization work together and should be used in tandem to ensure you're getting the most out of your EBQ environment.
Practical EBQ-specific tips
Use table partitioning and timestamp filtering
Always structure your SQL queries to leverage partitioned tables in BigQuery. Your EBQ tables are partitioned on the timestamp column. Apply filters on the timestamp partition column (the business timestamp for events) so only the relevant partitions are scanned. Filtering by timestamp drastically reduces the volume of data scanned, which is the primary driver of query cost in BigQuery.
Optimize query design
Query only necessary fields and columns, especially when dealing with nested records like the properties field — avoid SELECT * unless required. Where possible, work directly with the raw_properties fields for scheduled exports, as they have a consistent data type and are independent of schema changes.
Monitor data freshness before querying
Use the _system_load_log table to check when new data updates have completed before running dependent or scheduled queries. This prevents queries from running on incomplete or empty datasets, saving unnecessary costs.
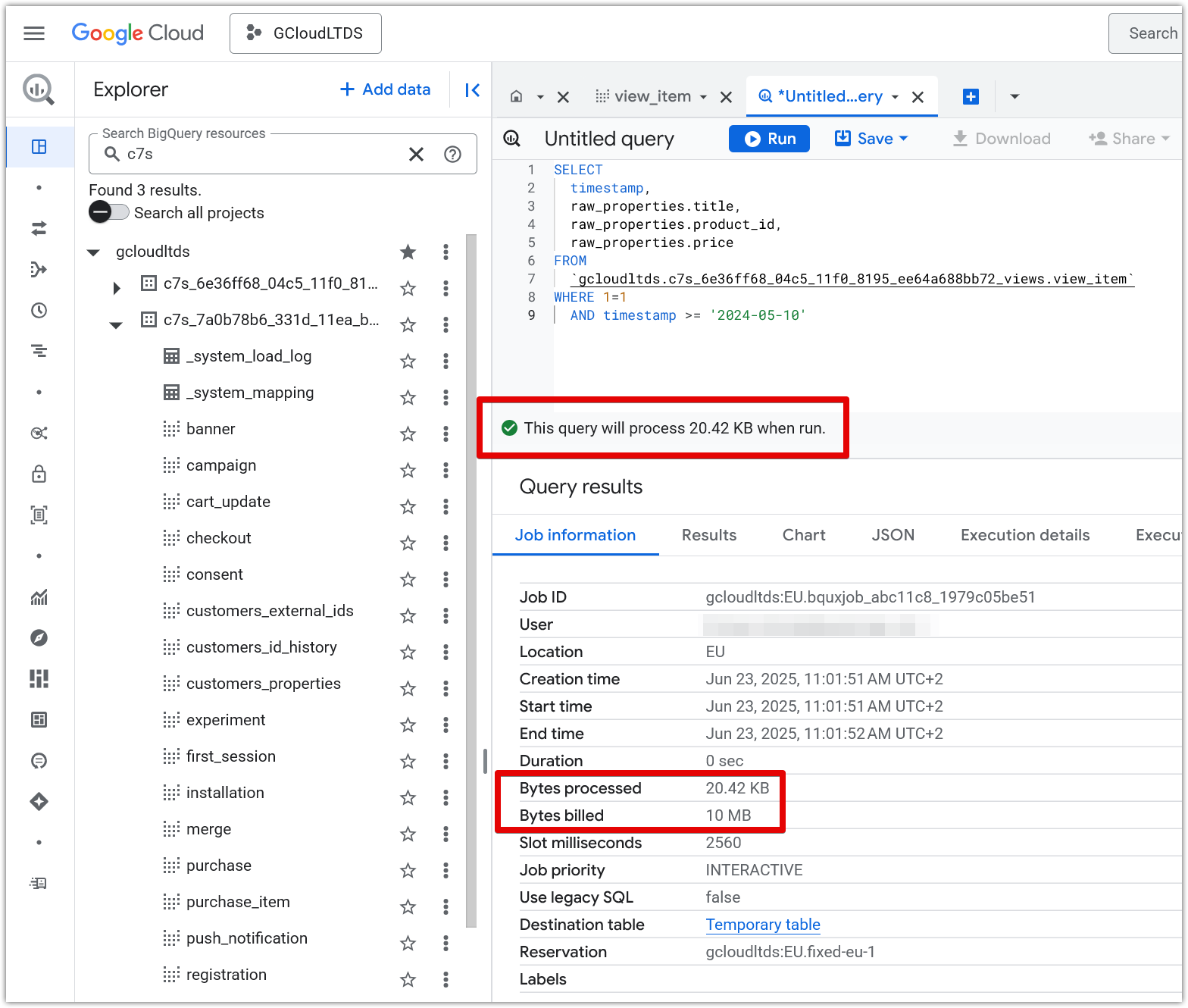
Estimate query costs before running:
Before executing a query, check how much data it will process to avoid unexpected costs.
- In the BigQuery Console: The query editor displays the estimated volume of data to be processed in the bottom right corner before you run the query. Use this as a quick check, especially for large datasets.
- From a script: Use the
dry_rundirective when calling the BigQuery API. A dry run validates the query and returns the estimated bytes to be processed without executing the query or returning results. See Google's dry run documentation for implementation details.
Automate and schedule processing outside EBQ
For resource-intensive queries or recurring calculations, use scheduled queries in your own BigQuery project (not on EBQ directly). Copy aggregated data from EBQ to your BigQuery first. You can persist heavy computation results in your tables, and then run lighter queries over smaller result sets.
Manage data retention and filtering
Since event deletions in Bloomreach aren't propagated to EBQ, manually filter out invalid, bugged, or redundant data during analysis. This keeps your result sets relevant and can help reduce processed data volumes.
Minimize unnecessary data processing
- Avoid joining large tables unless absolutely necessary.
- Use
ARRAY_AGGand similar BigQuery aggregation functions judiciously to minimize data shuffling. - Where applicable, pre-filter or aggregate at the earliest stage of your query pipeline to restrict the downstream data footprint.
Other tips
- Star or bookmark datasets and tables you use frequently for quick access (prevents accidental querying of the wrong datasets).
- Review your usage regularly and optimize queries based on the BigQuery query execution details, adjusting for data scanned and execution time.
After making changes, you can always verify if the optimized query is more efficient than the previous one before running it using the preview message displayed in the query editor window.
Updated 6 days ago