

Databricks
This guide introduces the Databricks integration with Bloomreach.
Integration overview
The Databricks integration connects your Databricks data lakehouse directly to Bloomreach, enabling automated data imports without manual file transfers or third-party middleware.
This integration supports importing customers, events, and catalogs with automatic synchronization as often as every 15 minutes.
Why use Databricks integration
-
Automated data imports: Set up scheduled, near-real-time data transfers from Databricks to Bloomreach. Your campaigns and analytics always use up-to-date information without manual intervention.
-
Reduced complexity: Eliminate time-consuming and error-prone SFTP file transfers or custom connectors. The integration handles data movement automatically.
-
Lower integration costs: Avoid extra expenses for middleware or manual processes. Reduce setup time and ongoing maintenance requirements.
-
Better support for AI features: Ensure Bloomreach's AI-powered tools, such as Loomi AI, have access to the latest customer and product data for more accurate insights and automation.
-
Enterprise-ready: The integration supports organizations already using Databricks or migrating to it, accommodating advanced analytics and marketing use cases.
Compute and cost
Each import runs SQL queries against your Databricks SQL Warehouse, which consumes compute resources (DBUs) on your Databricks account. You control costs by choosing the import schedule and the scope of data queried. Bloomreach covers the cost of storing and processing data on its side. There's no additional per-query charge from Bloomreach.
How Databricks integration works
The integration connects to Databricks and requires a one-time connection setup. Once configured, it can import from tables, views, and user-defined query results.
When importing from tables with change tracking enabled, the system automatically imports subsequent changes from Databricks as often as every 15 minutes to keep your data current.
Connection architecture
Bloomreach connects to your Databricks SQL Warehouse using the native Databricks SQL connector over HTTPS. This isn't a JDBC, ODBC, or Kafka connection. Here's what the connection uses:
- Transport: HTTPS (TLS-encrypted) to your Databricks SQL Warehouse endpoint.
- Authentication: OAuth machine-to-machine (M2M) via a Databricks service principal (Client ID and Client Secret).
- Addressing: Server hostname and HTTP path identify your SQL Warehouse; optional catalog and schema scope which data is accessible.
No middleware, Reverse ETL tooling, or third-party connectors are required.
Security
- Transport encryption: All communication between Bloomreach and your Databricks SQL Warehouse uses TLS-encrypted HTTPS. No data is transmitted in plaintext.
- Authentication and credential storage: The integration authenticates using a Databricks service principal (Client ID and Client Secret) via OAuth M2M. Credentials are stored encrypted at rest within Bloomreach's infrastructure.
- Access control: Bloomreach only accesses data that the service principal is authorized to read. Your Databricks Unity Catalog governance and table-level ACLs remain authoritative. We recommend creating a dedicated service principal with read-only access to the specific catalog, schema, and tables needed.
- Network controls: Bloomreach import workers connect from dynamic IP addresses.
Prerequisites
Access requirements
Before you set up the integration, make sure you have:
-
A Databricks service principal (Client ID and Client Secret) with access to the relevant catalog, schema, and tables. You may need account admin privileges to create the service principal.
-
Bloomreach account enabled with Data hub module enabled. Contact your Customer Success Manager to enable Databricks support for catalog imports in your project.
Data format requirements
Bloomreach has flexible data format requirements. During import setup, you map the source data format to the relevant data structure.
The following columns must be present in source tables or views:
| Data category | Required columns | Optional columns |
|---|---|---|
| Customers | ID to be mapped to the customer ID in Bloomreach (typically registered) | Timestamp to be mapped to update_timestamp |
| Events | ID to be mapped to the customer ID in Bloomreach (typically registered); Timestamp | |
| Catalog | ID to be mapped to the catalog item ID in Bloomreach (typically item_id) |
The following attribute data types are supported: text, long text, number, boolean, date, datetime, list, URL, and JSON.
Delta update requirements
Delta updates are supported for tables only. They aren't supported for views.
This feature requires delta.enableChangeDataFeed to be enabled on the source table in Databricks.
Enable the Change Data Feed using the following command:
ALTER TABLE myDeltaTable SET TBLPROPERTIES (delta.enableChangeDataFeed = true)For more details, see the Change Data Feed documentation by Databricks.
Set up Databricks integration
-
Go to Data & Assets > Integrations and click + Add new integration in the top right corner.
-
In the Available integrations dialog, enter "Databricks" in the search box.
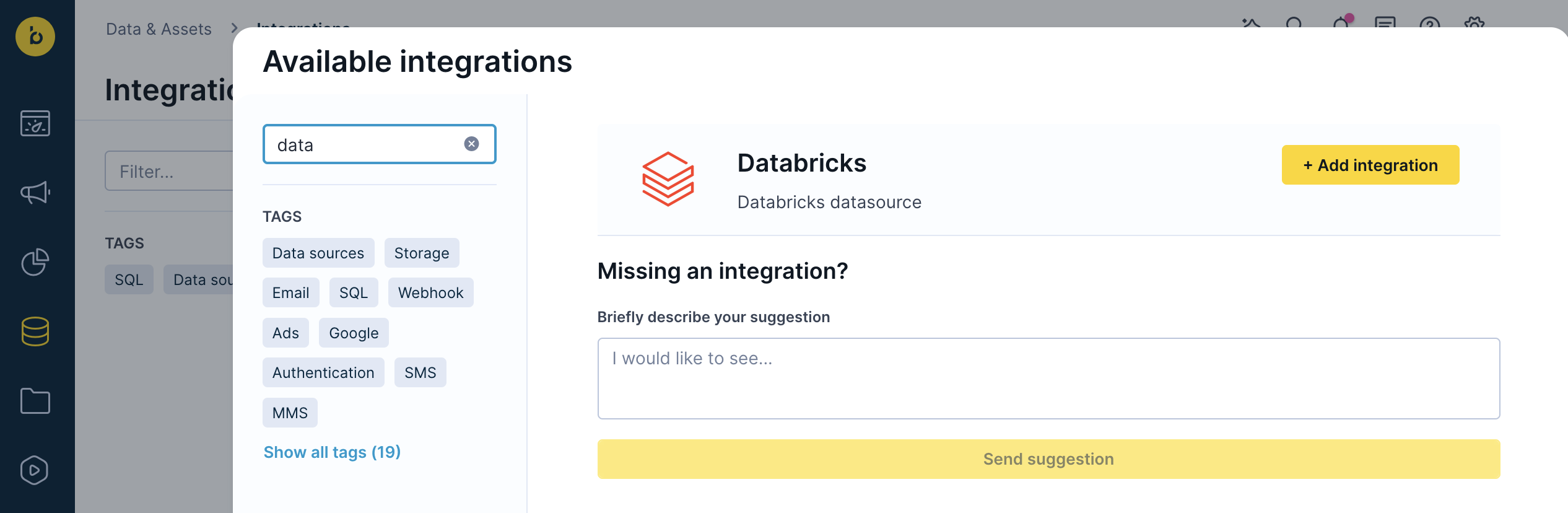
-
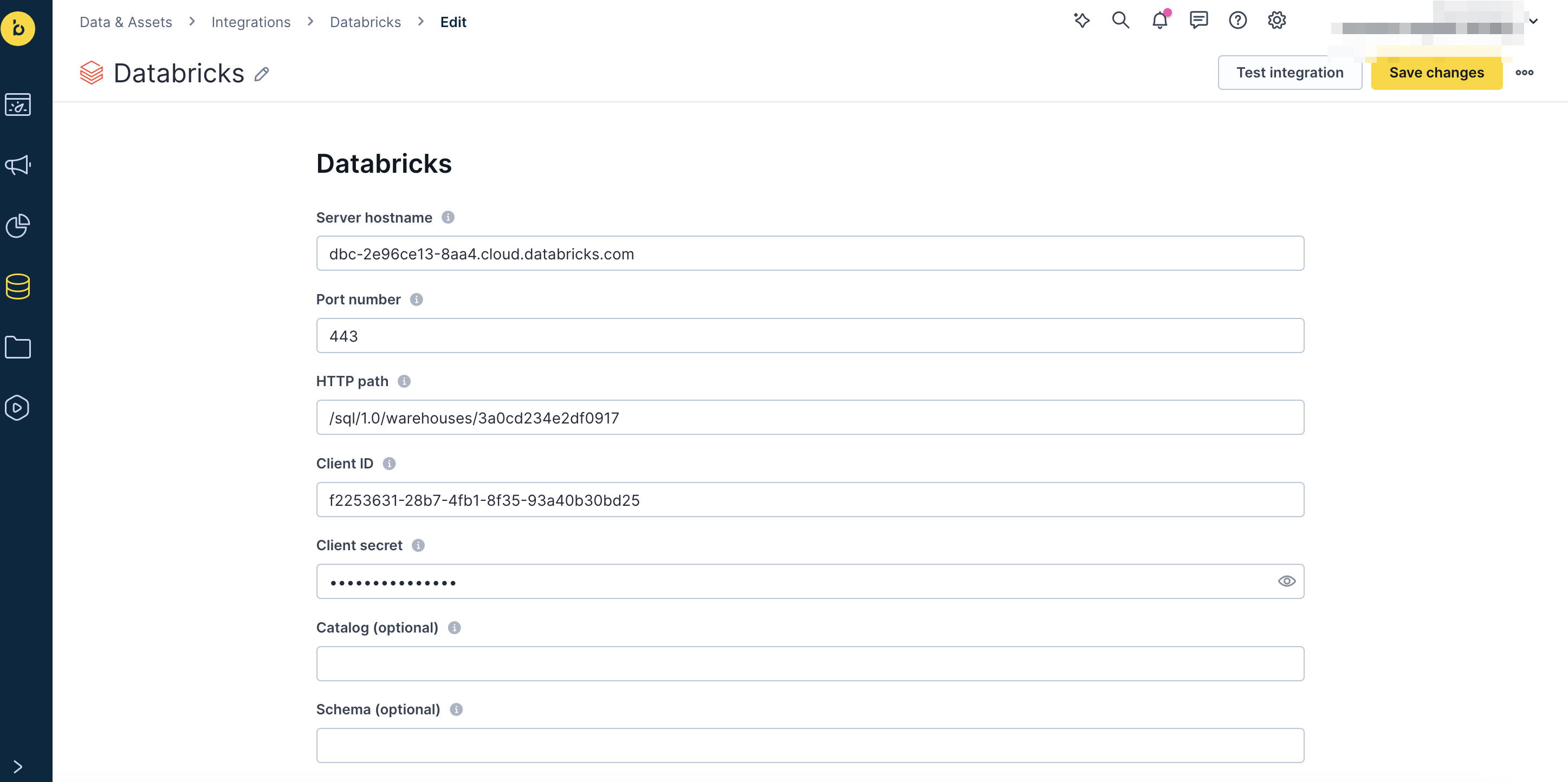
Fill in the following fields (tooltips guide you with the correct format):
-
Server hostname
-
Port number
-
HTTP path
-
Client ID
-
Client secret
-
Catalog (optional)
-
Schema (required if you specify a catalog)
-
-
Click Save integration.
ImportantRemoving the integration or deleting an import cancels all future delta updates. Data already imported from Databricks will remain in Bloomreach, and any import currently in progress will complete.
Import data from Databricks
The import process follows the same steps for all data types, with a few configuration differences for each type.
Import process
-
Go to Data & Assets > Imports and click + New import.
-
Select your data type (Customers, Events, or Catalog) and complete any type-specific selections.
-
Enter a name for the import (for example, Databricks customers import).
-
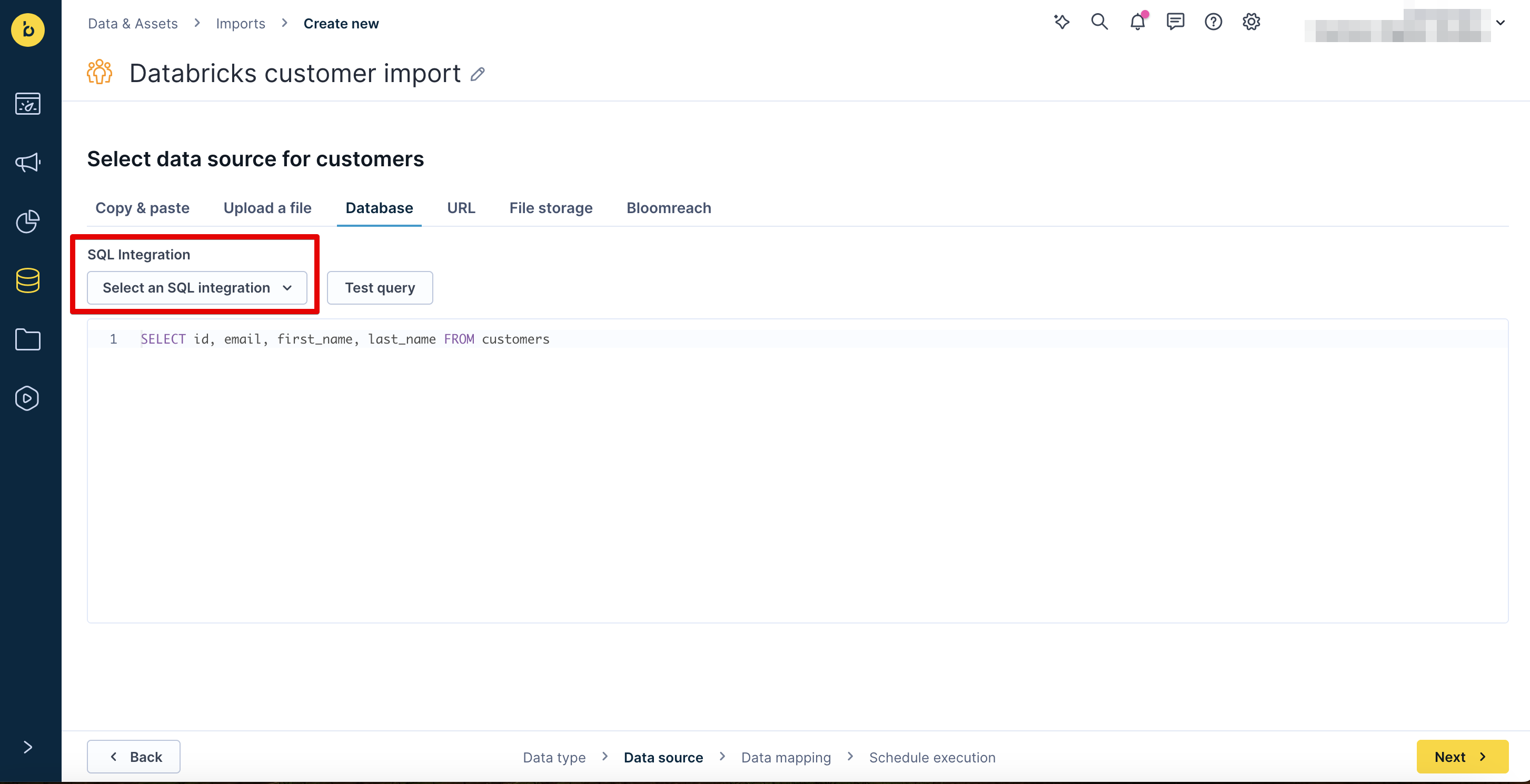
On the Database tab, in the SQL Integration dropdown, select the Databricks integration.
-
Select Table, then select the table from available tables/views, or Query to write a custom SQL query, to import from in the Source Table dropdown.
-
Click Preview data to verify the data source is working, then click Next.
-
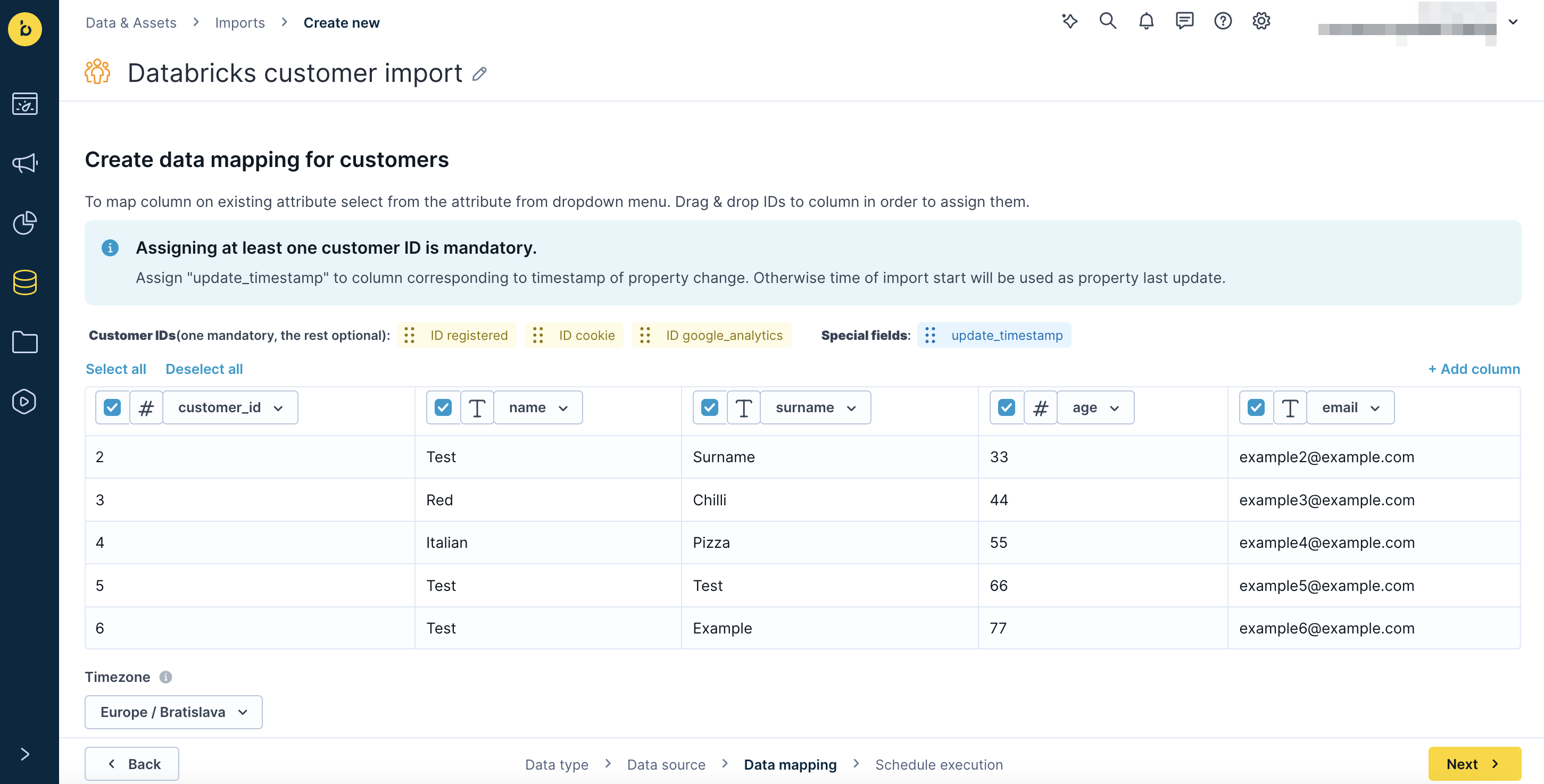
Map your ID to the matching column in the Databricks table using drag and drop, then click Next.
-
Configure your schedule and click Finish to start the import.
Customers
Map your customer ID (typically ID registered) to the matching column in the Databricks table.
As a best practice, add a timestamp column to your customer table that updates every time customer data changes. Map this column to update_timestamp during import setup. This prevents delta updates from overwriting customer property values that were tracked in Bloomreach since the previous import.
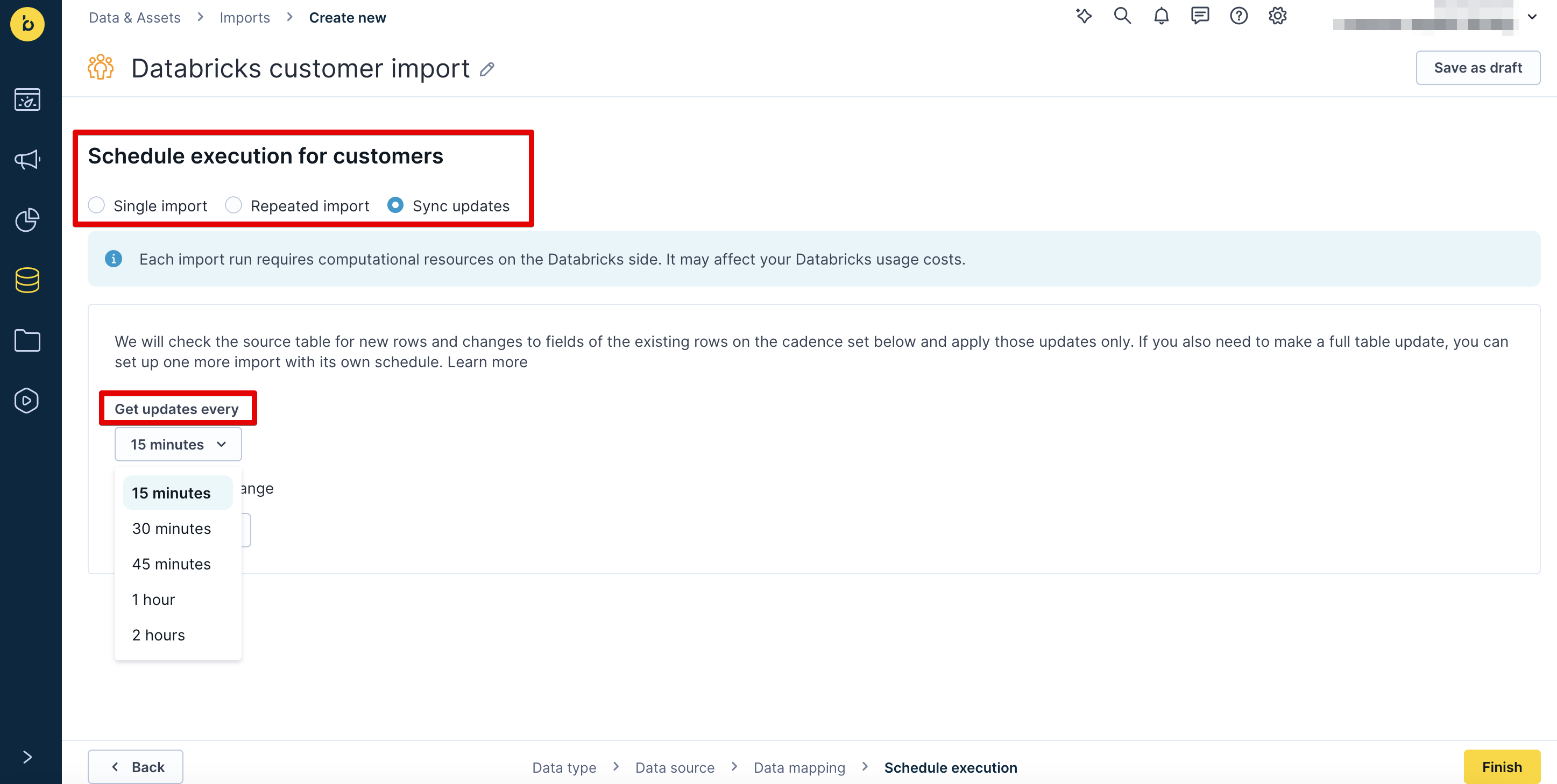
Schedule options
- Single import: A one-off import of all records.
- Repeated import: A scheduled, recurring import of all records.
- Sync updates: A scheduled, recurring delta import of changes since the previous import.
- Schedule frequency: Every 15, 30, or 45 minutes, 1 hour, or 2 hours, with an optional time range (start and end dates).
ImportantDeleting a customer profile in Bloomreach doesn't delete it in Databricks. If the record hasn't changed in Databricks since it was deleted in Bloomreach, it won't be recreated on the next sync. It will only be recreated if the record is updated in Databricks, which triggers the import job to re-import it.
Events
-
Select Events and select or enter the event type to import (for example, view), then click Next.
-
Map your customer ID (typically ID registered) to the matching column in the Databricks table.
-
Schedule options and frequency: Same as customers.
Use Sync updates to keep both platforms in sync. This generates compute costs on your Databricks side, so use it only for the most critical data. Use Single import for fixed data that doesn't change.
Important
- Each import handles one event type. To import multiple event types, set up a separate import for each.
- Events are unchangeable. Delta updates add new events but don't update previously imported ones.
Catalogs
Configure product data Databricks imports via Data hub imports. For general catalogs, follow the steps in Create and manage Data hub catalogs.
ImportantDeleting a catalog item in Bloomreach does not delete it in Databricks. If the record hasn't changed in Databricks since it was deleted in Bloomreach, it won't be recreated on the next sync. It will only be recreated if the record is updated in Databricks, which triggers the import job to re-import it.
Export data to Databricks
Exports can be done in scheduled mode only.
-
Export your data from Bloomreach using the Exports to Google Cloud Storage (GCS) option.
-
Store your data in a GCS-based data lake.
-
To load files into Databricks database tables, use LOAD. See the overview article by Databricks.
-
To trigger automatic file loading, call the public REST API endpoints. See the Databricks article on bulk loading from Google Cloud Storage for details.
Delete data in Bloomreach
Using the API, you can anonymize customers individually or in bulk. To delete customers, mark them with an attribute, filter by that attribute, and delete them manually in the UI.
You can delete events by filtering in the UI. Delete catalog items using the Delete catalog item API endpoint.
Example use cases
-
One-time imports: Import purchase history for historical analysis and segmentation.
-
Regular delta imports: Keep customer attributes in sync so marketing campaigns always use current data.
Limitations
- Delta updates don't support "delete" operations. If you delete a record in Databricks that was previously imported, it won't be deleted in Bloomreach on the next sync.
- Deleting a record in Bloomreach doesn't affect Databricks. The record remains in Databricks and will only be recreated in Bloomreach if it is updated in Databricks, which triggers the import job to re-import it.
- Importing from Databricks doesn't support static IP addresses. Bloomreach import workers connect from dynamic IP addresses, so IP allowlisting isn't available for this integration. If your network configuration requires static IPs, contact your Customer Success Manager.
More resources
Updated about 1 month ago