

Search high-level architecture
If you're new to Bloomreach Search, this article is a good starting point for understanding the overall architecture.
📘 Prerequisite knowledge
To understand this article, it is helpful to have the following prerequisite knowledge:
- E-commerce infrastructure: Familiarity with how e-commerce platforms work, including the role of product catalogs and shopper interactions.
- HTTP REST APIs: Knowledge of how RESTful APIs work.
- Event tracking: Familiarity with tracking user behavior and capturing event data for analytics and insights.
Architecture overview
The following visual will guide you through the Bloomreach architecture.
-
The left side indicates your (the customer's) infrastructure.
-
The clouds represent the touchpoints.
-
The yellow square encapsulates Bloomreach's infrastructure.
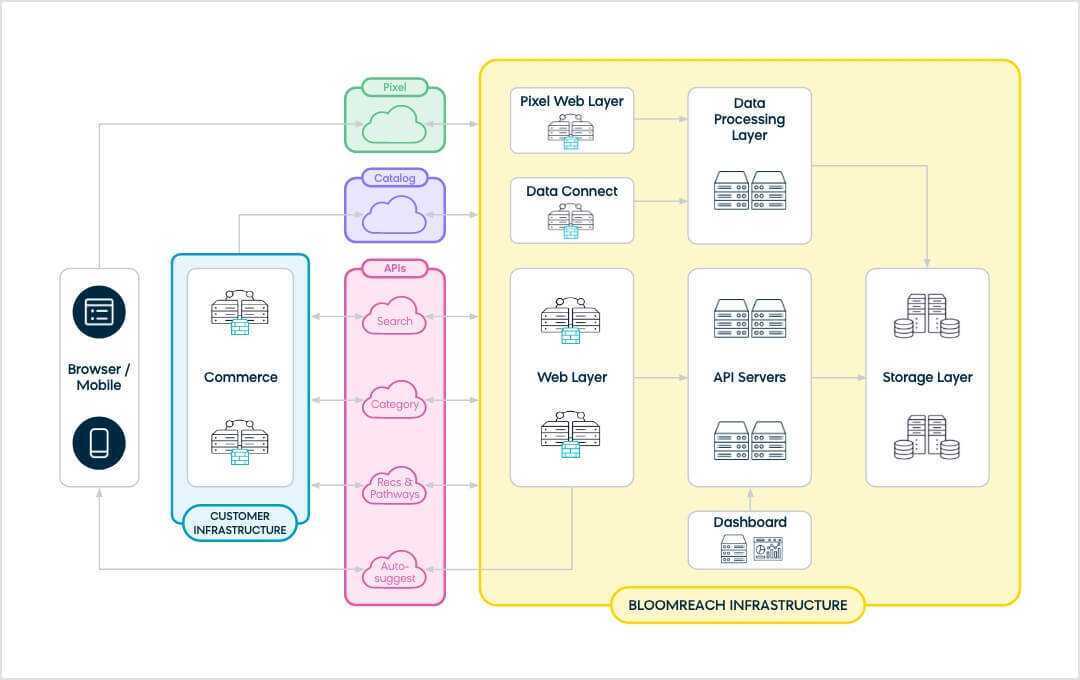
Key touchpoints
At a high level, it's important to know three essential touchpoints:
Pixel
Pixel allows Bloomreach to track your shoppers' behaviors and capture event data. This data helps with algorithm learning and generating actionable insights.
Catalog
The next piece is the catalog. This represents the products you sell, all the product attributes, and how you define categories. This data is ingested into Bloomreach via our Data Connect framework. There are three key steps to send and sync your catalog data:
-
Format data
The first step involves preparing the catalog data in a structured JSON-based format. -
Send data
The next step is sending data. You can control how often you send us the catalog data. This could be a full catalog feed (PUT) once every day or incremental feeds ( delta PATCH ) throughout the day. This data can be sent via:- SFTP: A file that you place on the SFTP server that we host
or - API: For incremental changes
- SFTP: A file that you place on the SFTP server that we host
-
Index data
In the next step, you initiate a call to perform an index. When indexing is complete, all the changes made to the catalog will be visible on your site.
APIs
The last piece is leveraging our APIs. This depends on which Bloomreach products you are setting up in your integration. The above example includes search and category, recommendations and pathways, and autosuggest (type-ahead API associated with searches).
You may make server-side or front-end calls as required. Bloomreach APIs are HTTP REST APIs, where you can send parameters that control what the request accomplishes. The response contains a JSON object that retrieves data per your request. Suppose you make a search call; the response includes the following information:
- All the products for the search
- Facet information related to the search
- Any metadata like the number of records for the query
- Information on whether the query was spell-corrected or relaxed
- Debug section (if you enable it), where you can see the actual scores associated with each item returned by our algorithms
- Information about the merchandising rules you applied that affected the query
Updated 6 days ago